Complete guide for migrating your data from Dgraph Cloud to a self-managed Dgraph cluster on Google Kubernetes Engine (GKE) or Amazon Elastic Kubernetes Service (EKS)
This guide walks you through migrating your data from Dgraph Cloud to a self-managed Dgraph cluster running on Google Kubernetes Engine (GKE) or Amazon Elastic Kubernetes Service (EKS).
kubectl is the command-line interface (CLI) tool for interacting with Kubernetes clusters. It’s your primary way to communicate with and control Kubernetes from the command line.kubectl allows you to:
Deploy and manage applications on Kubernetes
Inspect and manage cluster resources (pods, services, deployments, etc.)
# List all podskubectl get pods# List pods in specific namespacekubectl get pods -n dgraph# List services and deploymentskubectl get serviceskubectl get deployments# List cluster nodeskubectl get nodes
Debugging & Logs
Copy
Ask AI
# View pod logskubectl logs dgraph-alpha-0 -n dgraph# Follow logs in real-timekubectl logs -f dgraph-alpha-0 -n dgraph# Get detailed pod informationkubectl describe pod dgraph-alpha-0 -n dgraph# Execute shell inside podkubectl exec -it dgraph-alpha-0 -n dgraph -- bash
Managing Resources
Copy
Ask AI
# Apply configuration from filekubectl apply -f dgraph-alpha.yaml# Delete resourceskubectl delete pod dgraph-alpha-0 -n dgraphkubectl delete -f dgraph-alpha.yaml# Port forwarding for local accesskubectl port-forward service/dgraph-alpha-public 8080:8080 -n dgraph
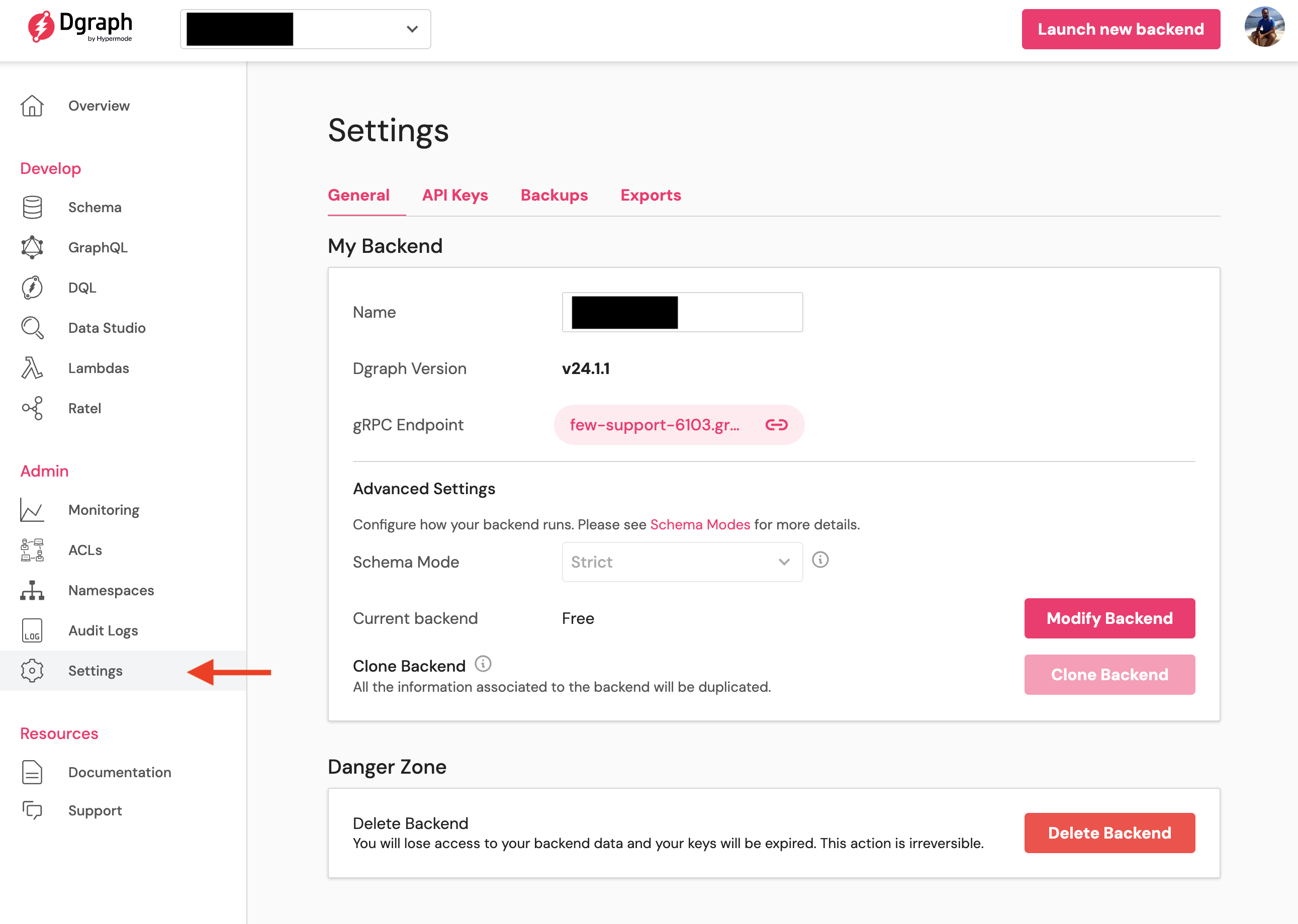
Log into your Dgraph Cloud dashboard and navigate to your cluster.
2
Navigate to Export
Click on the “Export” tab in your cluster management interface.
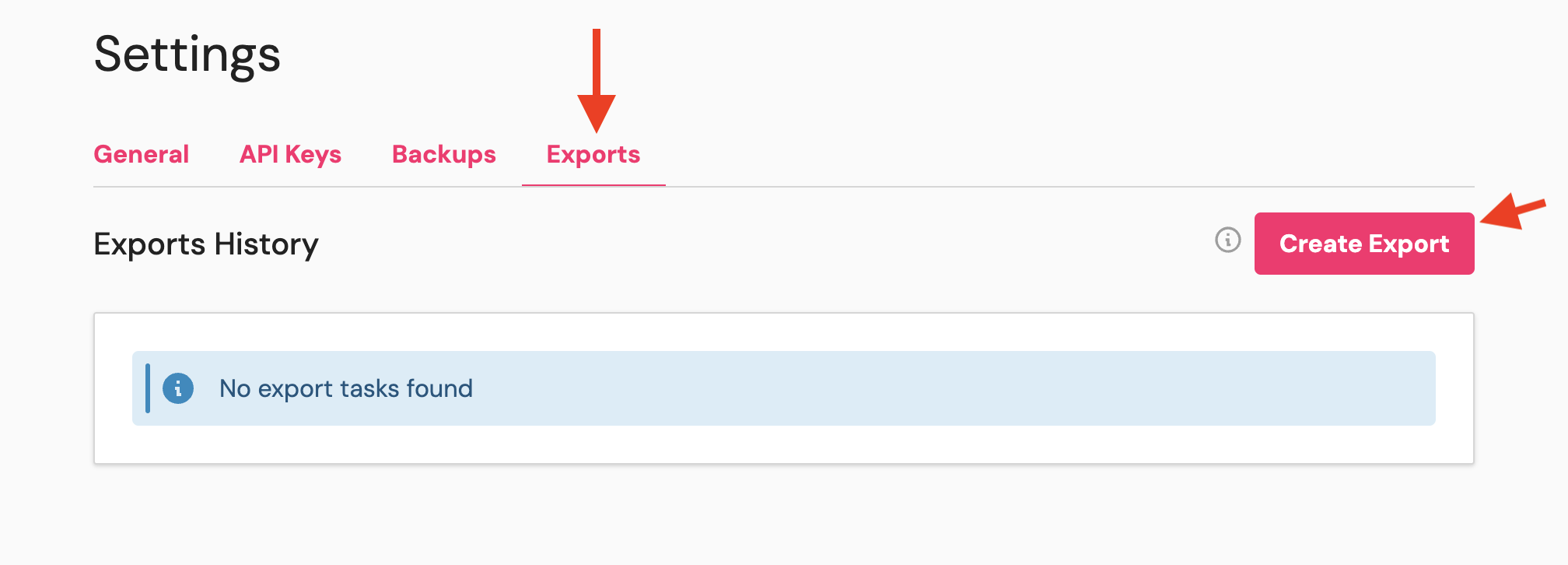
3
Configure Export Settings
Select your export format and destination.
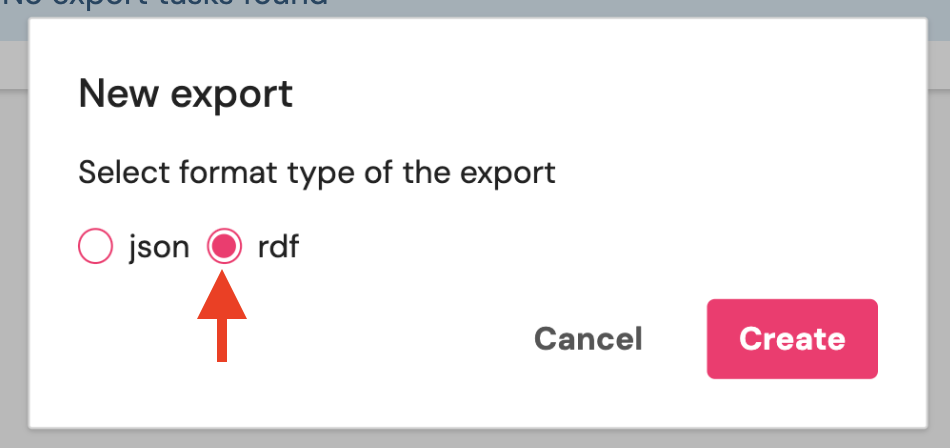
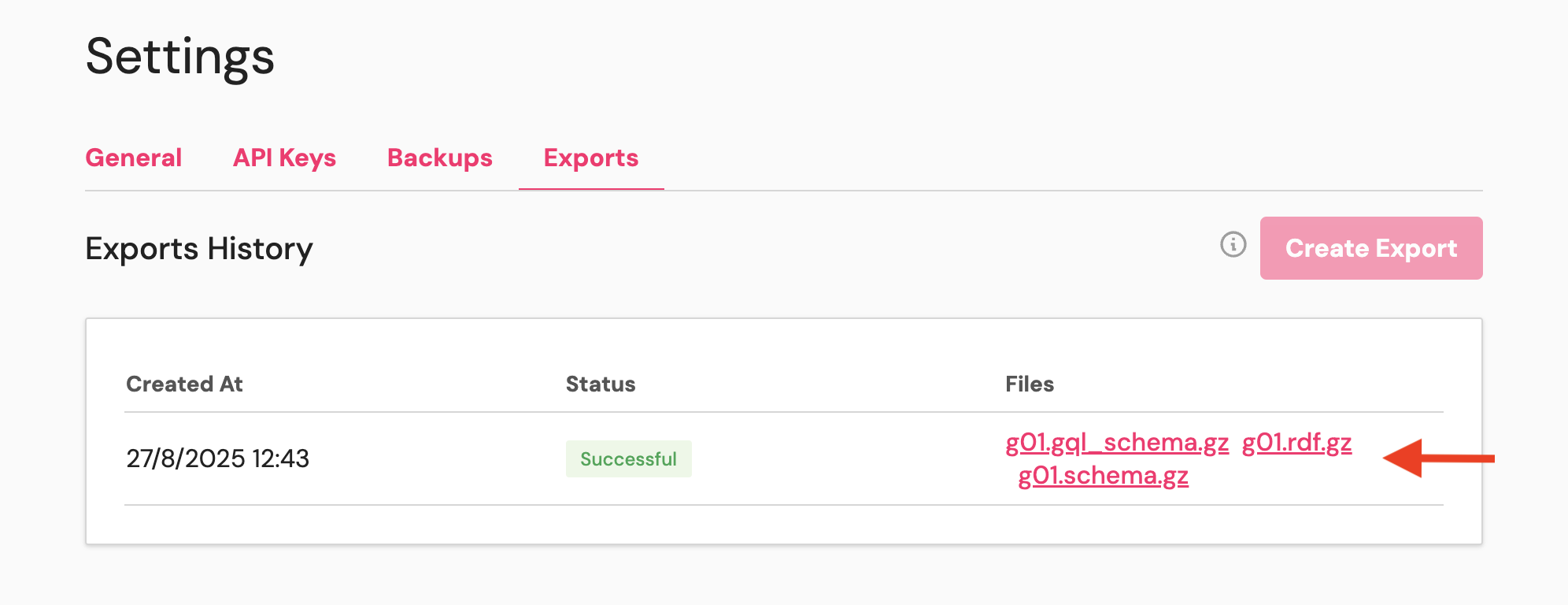
Dgraph Cloud supports JSON or RDF.\Click “Start Export” and monitor the progress. Large datasets may take several
hours.
Click “Start Export” and monitor the progress. Large datasets may take several
hours.
curl -X POST https://your-cluster.grpc.cloud.dgraph.io/admin \ -H "Content-Type: application/json" \ -d '{"query": "{ state { groups { id members { id addr leader lastUpdate } } } }"}'
What is a Namespace?
A Kubernetes namespace is a way to divide cluster resources between multiple users or projects. In this guide, we create a dgraph namespace to logically isolate all Dgraph-related resources (pods, services, volumes, etc.) from other workloads in your cluster. This makes management, access control, and resource monitoring easier.What is a Storage Class?
A StorageClass in Kubernetes defines the type of storage (such as SSD or HDD) and its parameters (like performance, replication, or zone) for dynamically provisioned persistent volumes. By creating a StorageClass (e.g., fast-ssd), you tell Kubernetes how to create and manage storage for Dgraph pods, ensuring the right performance and durability for your data.
If you are using GKE, you can use the GKE Storage Class.
If you are using EKS, you can use the EKS Storage Class.
GKE Storage Class
EKS Storage Class
Create dgraph-namespace-gke.yaml file with the following content:
What is a Helm Chart?
A Helm chart is a package of pre-configured Kubernetes resources that makes it easy to deploy and manage complex applications on Kubernetes clusters. Helm acts as a package manager for Kubernetes, similar to how apt or yum work for Linux distributions. A Helm chart defines all the resources (like Deployments, Services, StatefulSets, ConfigMaps, etc.) needed to run an application, along with customizable parameters.Why use Helm Charts for Dgraph on Managed Kubernetes?
When using a managed Kubernetes service (such as GKE, EKS, or AKS), Helm charts simplify the deployment process by automating the creation and configuration of all the necessary Kubernetes resources for Dgraph. Dgraph maintains official Helm charts that encapsulate best practices for running Dgraph in production, including resource requests, persistent storage, replica management, and service exposure. By using these charts, you avoid manual configuration errors, ensure compatibility with Kubernetes best practices, and can easily upgrade or roll back your Dgraph deployment as needed.
What is a LoadBalancer?
A LoadBalancer is a Kubernetes service type that creates a load balancer in front of a set of Pods. It allows you to expose your Dgraph services to the internet or to a private network.
What is an Ingress?
An Ingress is a Kubernetes resource that allows you to manage external access to your Dgraph services. It can route traffic to different services based on the hostname or path.
EKS LoadBalancer
GKE LoadBalancer
Create dgraph-alpha-eks.yaml file with the following content:
Deploy the configuration with kubectl apply -f dgraph-alpha-eks.yaml:
Deploy Alpha
Copy
Ask AI
kubectl apply -f dgraph-alpha-eks.yaml# Wait for Alpha pods to be readykubectl wait --for=condition=ready pod -l app=dgraph-alpha -n dgraph --timeout=300s
Create dgraph-alpha-gke.yaml file with the following content:
Deploy the configuration with kubectl apply -f dgraph-alpha-gke.yaml:
Deploy Alpha
Copy
Ask AI
kubectl apply -f dgraph-alpha-gke.yaml# Wait for Alpha pods to be readykubectl wait --for=condition=ready pod -l app=dgraph-alpha -n dgraph --timeout=300s
The import process will download data from cloud storage and load it into your Dgraph cluster. Ensure your cluster has sufficient resources and storage.
# Add annotation to service for Google-managed SSLmetadata: annotations: cloud.google.com/neg: '{"ingress": true}' kubernetes.io/ingress.global-static-ip-name: "dgraph-ip"
Copy
Ask AI
# Add annotation to service for ACM SSLmetadata: annotations: service.beta.kubernetes.io/aws-load-balancer-ssl-cert: "arn:aws:acm:us-west-2:ACCOUNT-ID:certificate/CERTIFICATE-ID" service.beta.kubernetes.io/aws-load-balancer-backend-protocol: "http" service.beta.kubernetes.io/aws-load-balancer-ssl-ports: "https"
Check if sufficient resources are available in your cluster:
Copy
Ask AI
kubectl describe nodeskubectl get events -n dgraph --sort-by='.metadata.creationTimestamp'
Import fails
Verify cloud storage permissions and file formats:
GCP Troubleshooting
AWS Troubleshooting
Copy
Ask AI
# Check job logs for detailed error messageskubectl logs job/dgraph-data-import -n dgraph# Verify files in Cloud Storagegsutil ls -la gs://your-dgraph-backups/# Test service account permissionskubectl exec -it dgraph-data-import-xxxxx -n dgraph -- gsutil ls gs://your-dgraph-backups/
Copy
Ask AI
# Check job logs for detailed error messageskubectl logs job/dgraph-data-import -n dgraph# Verify files in S3aws s3 ls s3://your-dgraph-backups/ --recursive# Test IAM role permissionskubectl exec -it dgraph-data-import-xxxxx -n dgraph -- aws s3 ls s3://your-dgraph-backups/
Connection issues
Check service discovery and network policies:
Copy
Ask AI
# Check service endpointskubectl get endpoints -n dgraph# Test internal connectivitykubectl exec -it dgraph-alpha-0 -n dgraph -- nslookup dgraph-zero.dgraph.svc.cluster.local# Check LoadBalancer statuskubectl describe service dgraph-alpha-public -n dgraph
Test this migration process thoroughly in a staging environment before migrating production data. Always maintain backups of your original data during the migration process.